1. TextCNN
1.1 What TextCNN is
1.1.1 Paper
Yoon Kim proposed TextCNN in the paper (2014 EMNLP) Convolutional Neural Networks for Sentence Classification.
The convolutional neural network CNN is applied to text classification tasks, and multiple kernels of different sizes are used to extract key information in sentences (similar to n-grams with multiple window sizes), so as to better capture local correlations.
1.1.2 Network Structure
The structure is as follow:
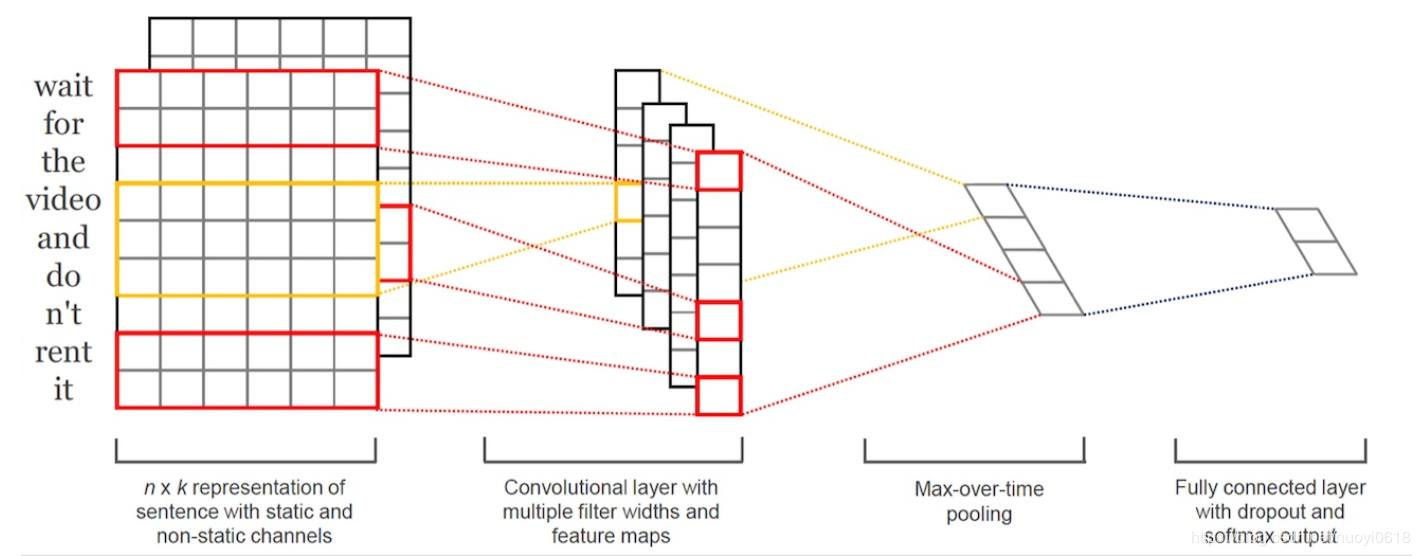
The schematic diagram is as follows:
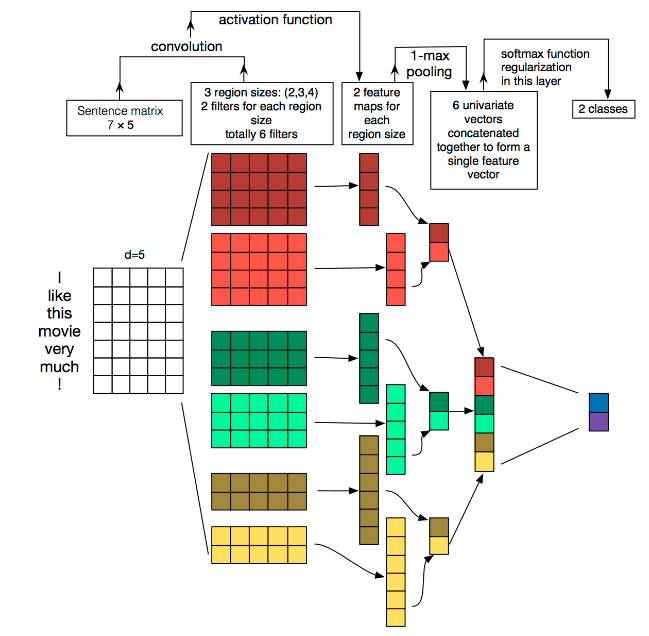
- Embedding: The first layer is the 7 by 5 sentence matrix on the leftmost side of the picture. Each row is a word vector with dimension = 5. This can be analogous to the original pixels in the image.
- Convolution: Then go through a one-dimensional convolutional layer with kernel_sizes=(2,3,4), each kernel_size has two output channels.
- MaxPolling: The third layer is a 1-max pooling layer, so that sentences of different lengths can become fixed-length representations after passing through the pooling layer.
- FullConnection and Softmax: Finally, a fully connected softmax layer is connected to output the probability of each category.
1.2 Practice
1 | import logging |
2. TextRNN
TextRNN uses RNN (recurrent neural network) for text feature extraction. Since text itself is a sequence, LSTM is naturally suitable for modeling sequence data. TextRNN inputs the word vector of each word in the sentence to the bidirectional double-layer LSTM in turn, and stitches the hidden layer at the last valid position in the two directions into a vector as the representation of the text.
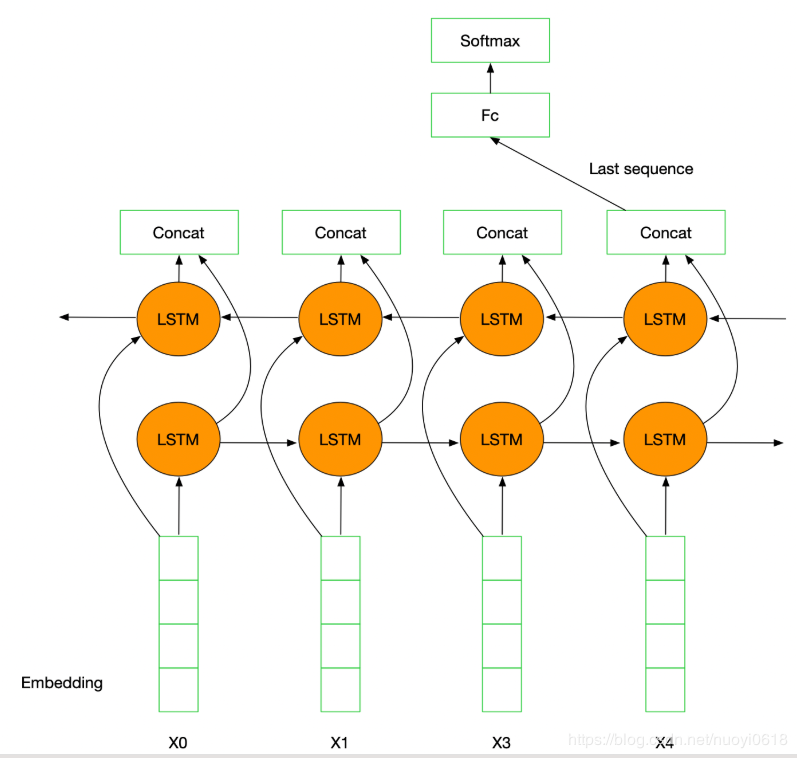
Introduce bidirectional LSTM for classification; the general process is:
- embeddding layer;
- Bi-LSTM layer;
- concat output;
- FC layer;
- softmax;
practice
1 | import numpy as np |

