
CV初探
CV是什么
计算机视觉(Computational Vision),英文简写CV,是一门“赋予机器自然视觉能力”的学科,是使用计算机模仿人类视觉系统的科学,让计算机拥有类似人类 提取、处理、理解和分析图像以及图像序列的能力。它是一门包含领域很广的综合性学科。从现阶段的研究来看,计算机视觉试图建立一种人工系统,提出的越来越多的理论和技术主要目的是为了从图像或者多维数据中获取信息。
CV可以解决什么问题
好奇CV可以做什么,是一个比较适用的兴趣点和动力源。一般来说,CV的目标是”看到“。其在具体应用中往往都要解决一些相同的问题,这些问题包括:
- 识别 —— ”看到“图像中的特定目标并能识别出来。
- 运动 —— ”看到“序列图像中物体的运动和自己在运动,或跟踪运动的物体。
- 场景重建 —— ”看到“序列图像并建立起完整的三维表面模型。
- 图像恢复 —— ”看到“一些被影响的部分背后的内容,主要是移除噪声和改善模糊状态
CV工程的常见步骤
简单了解一下工程方面的步骤,有利于知道后续的实践和增加对CV的认识。一般来说,CV工程分为以下5步:
- 图像获取 —— 通过各种图像感知器获取需要的图像数据。
- 预处理 —— 通过对图像进行一定的预处理来使其满足后续的操作要求。
- 特征提取 —— 从图像中提取各种复杂度的特征,以便识别目标。
- 检测/分割 —— 处理过程中,可能需要进一步分割有价值的部分用于后继处理。例如分割出包含特定目标的部分。
- 高级处理 —— 根据具体应用的需要,验证得到的数据是否符合要求,估测特定的系数等。
赛题理解
通过比赛来实践是一个学习的捷径,在压力之下可能会打破自己原来设定的界限,做到自我突破。当然,对我们这种新手来说,还是要脚踏实地一步一步来的。先来了解下Datawhale与天池联合发起的零基础入门系列赛事第二场 —— 零基础入门CV赛事之街景字符识别。
- 赛题名称:零基础入门CV之街道字符识别
- 赛题目标:通过这道赛题可以引导大家走入计算机视觉的世界,主要针对竞赛选手上手视觉赛题,提高对数据建模能力。
- 赛题任务:赛题以计算机视觉中字符识别为背景,要求选手预测街道字符编码,这是一个典型的字符识别问题。
为了简化赛题难度,赛题数据采用公开数据集SVHN,因此大家可以选择很多相应的paper作为思路参考。赛题数据
赛题以街道字符为赛题数据,数据集报名后可见并可下载,该数据来自公开数据集SVHN收集的街道字符,并进行了匿名采样处理。
注意: 按照比赛规则,所有的参赛选手只能使用比赛给定的数据集完成训练,不能使用SVHN原始数据集进行训练。比赛结束后将会对Top选手进行代码审核,违规的选手将清除排行榜成绩。
训练集数据包括3W张照片,验证集数据包括1W张照片,每张照片包括颜色图像和对应的编码类别和具体位置;为了保证比赛的公平性,测试集A包括4W张照片,测试集B包括4W张照片。
需要注意的是本赛题需要选手识别图片中所有的字符,为了降低比赛难度,该赛题还提供了训练集、验证集和测试集中所有字符的位置框。
数据标签
对于训练数据每张图片将给出对应的编码标签和具体的字符框的位置(训练集、测试集和验证集都给出字符位置),可用于模型训练:
| Field | Description |
|---|---|
| top | 左上角坐标X |
| height | 字符高度 |
| left | 左上角最表Y |
| width | 字符宽度 |
| label | 字符编码 |
字符的坐标具体如下所示: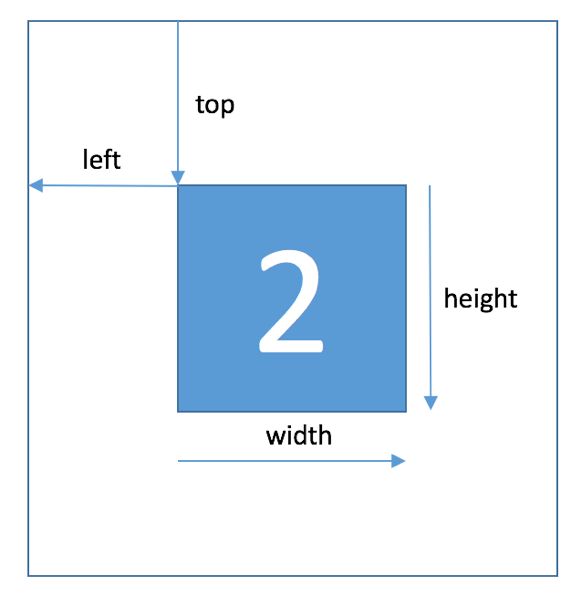
在比赛数据(训练集、测试集和验证集)中,同一张图片中可能包括一个或者多个字符,因此在比赛数据的JSON标注中,会有多个字符的边框信息:
| 原始图片 | 图片JSON标注 |
|---|---|
 |
 |
评测指标
选手提交结果与实际图片的编码进行对比,以编码整体识别准确率为评价指标。任何一个字符错误都为错误,最终评测指标结果越大越好,具体计算公式如下:
Score = 编码识别正确的数量 / 测试集图片数量
读取数据
这里给出JSON中标签的读取方式:
1 | import json |
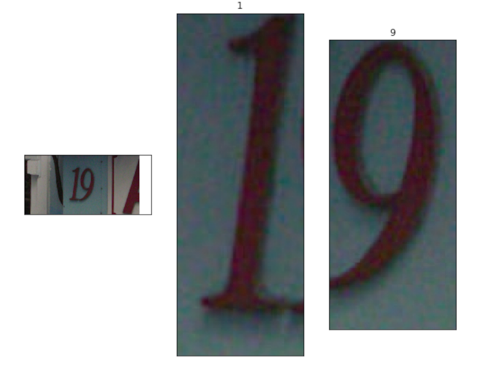
解题思路
赛题思路分析:赛题本质是一个分类识别问题,需要对图片的字符进行识别。但赛题给定的数据图片中不同图片中包含的字符数量不等。如下图所示,有的图片的字符个数为2,有的图片字符个数为3,有的图片字符个数为4。
| 字符属性 | 图片 |
|---|---|
| 字符:42 字符个数:2 |  |
| 字符:241 字符个数:3 |  |
| 字符:7358 字符个数:4 |  |
因此本次赛题的难点是需要对不定长的字符进行识别,与传统的图像分类识别任务有所不同。
解题思路探索
Datawhale给出了三种思路:
1、简单入门思路:定长字符识别
可以将赛题抽象为一个定长字符识别问题,在赛题数据集中大部分图像中字符个数为2-4个,最多的字符个数为6个。
因此可以对于所有的图像都抽象为6个字符的识别问题,字符23填充为23XXXX,字符231填充为231XXX。
经过填充之后,原始的赛题可以简化了6个字符的分类问题。在每个字符的分类中会进行11个类别的分类,假如分类为填充字符,则表明该字符为空。可参考Google2014年的论文《Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks》,该论文提出了基于深度卷积神经网络的定长字符分类识别方法。
2、专业字符识别思路:不定长字符识别

在字符识别研究中,有特定的方法来解决此种不定长的字符识别问题,比较典型的有CRNN字符识别模型。
CRNN采取的架构是CNN+RNN+CTC,cnn提取图像像素特征,rnn提取图像时序特征,而ctc归纳字符间的连接特性。CRNN能够获取不同尺寸的输入图像,并产生不同长度的预测。它直接在粗粒度的标签(例如单词)上运行,在训练阶段不需要详细标注每一个单独的元素(例如字符)。
此外,由于CRNN放弃了传统神经网络中使用的全连接层,因此得到了更加紧凑和高效的模型。所有这些属性使得CRNN成为一种基于图像序列识别的极好方法。
在本次赛题中给定的图像数据都比较规整,可以视为一个单词或者一个句子。
3、专业分类思路:检测再识别
在赛题数据中已经给出了训练集、验证集中所有图片中字符的位置,因此可以首先将字符的位置进行识别,利用物体检测的思路完成。
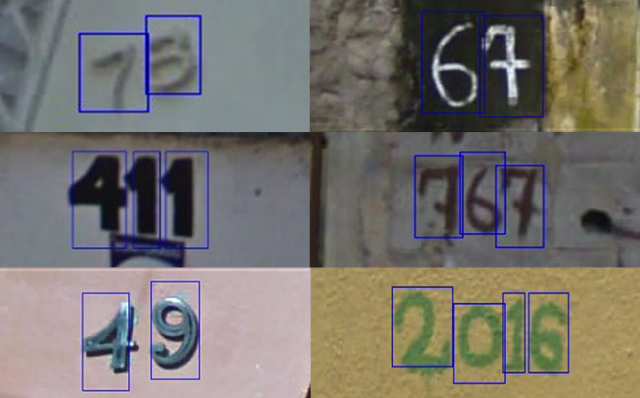
此种思路需要参赛选手构建字符检测模型,对测试集中的字符进行识别。选手可以参考物体检测模型SSD或者YOLO来完成。
SSD算法是一种直接预测目标类别和bounding box的多目标检测算法。与faster rcnn相比,该算法没有生成 proposal 的过程,这就极大提高了检测速度。针对不同大小的目标检测,传统的做法是先将图像转换成不同大小(图像金字塔),然后分别检测,最后将结果综合起来(NMS)。而SSD算法则利用不同卷积层的 feature map 进行综合也能达到同样的效果。算法的主网络结构是VGG16,将最后两个全连接层改成卷积层,并随后增加了4个卷积层来构造网络结构。
YOLO(You Only Look Once: Unified, Real-Time Object Detection),是Joseph Redmon和Ali Farhadi等人于2015年提出的基于单个神经网络的目标检测系统。YOLO是一个可以一次性预测多个Box位置和类别的卷积神经网络,能够实现端到端的目标检测和识别,其最大的优势就是速度快。事实上,目标检测的本质就是回归,因此一个实现回归功能的CNN并不需要复杂的设计过程。YOLO没有选择滑动窗口(silding window)或提取proposal的方式训练网络,而是直接选用整图训练模型。这样做的好处在于可以更好的区分目标和背景区域,相比之下,采用proposal训练方式的Fast-R-CNN常常把背景区域误检为特定目标。
小结
综上所示,本次赛题虽然是一个简单的字符识别问题,但有多种解法可以使用到计算机视觉领域中的各个模型,是非常适合CV入门学习的。解题思路中由浅至深分析了一个分类识别的问题,也是很有参考价值的,也算是给我们这样的初学者指出了一条不断深入和从不同角度分析解决问题的路子。
鸣谢与参考
References

